本文介绍的是上海应用技术大学戴翠霞教授课题组对基于Vision Transformer的视网膜病变计算机辅助诊断的研究,发表在《Journal of Innovative Optical Health Sciences》期刊2022年第2期。
Computer-aided Diagnosis of Retinopathy based on Vision Transformer
基于Vision Transformer的视网膜病变计算机辅助诊断
ZhencunJiang,Lingyang Wang, QixinWu,Yilei Shao,Meixiao Shen,Wenping Jiang,Cuixia Dai
研究背景
年龄相关性黄斑变性(AMD)和糖尿病性黄斑水肿(DME)是老年人常见的两种视网膜疾病,及时、准确的诊断对这些疾病的治疗至关重要。随着近年来图像分类技术的快速发展,计算机辅助诊断(CAD)被广泛地应用于各种疾病的快速诊断。其中,CAD在视网膜疾病的诊断中起到越来越重要的作用。在计算机辅助诊断的相关研究中,除了最常见的基于卷积神经网络(CNN)的VGG系列模型、Resnet系列模型等图像分类模型,2020年提出的Vision Transformer是一种新的图像分类模型,被认为是目前最好的图像分类模型,表现出了优于传统卷积神经网络模型的性能。Vision Transformer不依赖于任何CNN,完全基于Transformer结构设计,具有与CNN不同的特征提取方法。
内容简介
本文提出了一种利用Vision Transformer的计算机辅助诊断方法对光学相干断层扫描(OCT)图像进行分析以自动区分AMD图像、DME图像和正常眼睛图像,其分类准确率达到99.69%。经过模型剪枝的操作后,在保证分类准确率没有下降的前提下,识别时间达到了0.010秒。与卷积神经网络(CNN)图像各分类模型相比,剪枝后的Vision Transformer表现出更好的识别能力。
图文导读
1.正常眼睛和两种视网膜疾病的OCT图像

图1:正常眼睛和两种视网膜疾病的OCT图像示意图:a.正常 b.AMD c.DME
2.编码器结构

图2 编码器结构
Vision Transformer完全基于Transformer结构实现。一般的Transformer结构由一组编码器(Encoder)组件和一组解码器(Decoder)组件组成,而Vision Transformer是一种图像分类模型,不需要解码,因此不需要解码器组件,在Vision Transformer中的Transformer结构只有编码器组件。编码器组件是由6个相同的编码器组成的,每个编码器由一个多头注意层和一个全连接前馈层组成,并且这两个层都包含残差结构和层规范结构。
3.Vision Transformer识别OCT图像的结构图
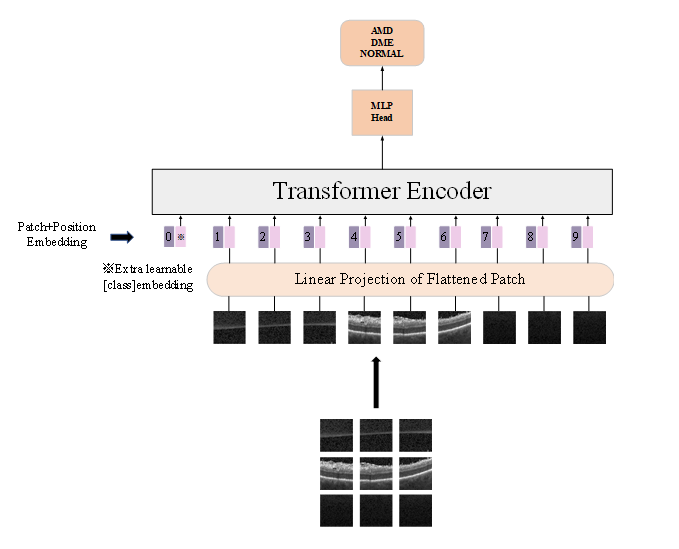
图3:Vision Transformer识别OCT图像的结构图
如图3,将图片切分成多个小块(Patch),对每一个Patch进行Patch Embedding的操作。Embedding是自然语言处理(Natural Language Processing, NLP)当中常用的一种空间映射方法,将高维向量映射到低维空间。也就是说,Embedding是一种降维操作,它可以有效的减少变量的维度,使得复杂的离散数据变得相对连续,而Patch Embedding即对Patch做Embedding的操作,将每个Patch都展平为一维的张量。Transformer结构要求输入的变量是向量形式,即一个二维矩阵,但是图像是一个三维矩阵,因此需要使用Embedding的操作使得图像的三维矩阵降维变成二维矩阵。在经过Patch Embedding的操作后,添加Positional Embedding和Class Embedding一起输入到Transformer Encoder当中。Positional Embedding指的是位置向量序列,用于引入位置信息,它的维度大小和经过Patch Embedding的图像的维度大小相同。Class Embedding的维度和经过Patch Embedding的图像的维度大小也相同,它是用于分类的向量序列。由Transformer Encoder输出后,会经过一个MLP Head结构,这是由全连接层和激活函数组成的,这里使用的激活函数为高斯线性误差单元(Gaussian Error Linear Unit,GELU )。模型的输出为OCT图像是正常眼睛、AMD或DME的概率,概率最高的即为最终的预测结果。
4.训练集的误差变化曲线和验证集的准确率变化曲线如图4所示。
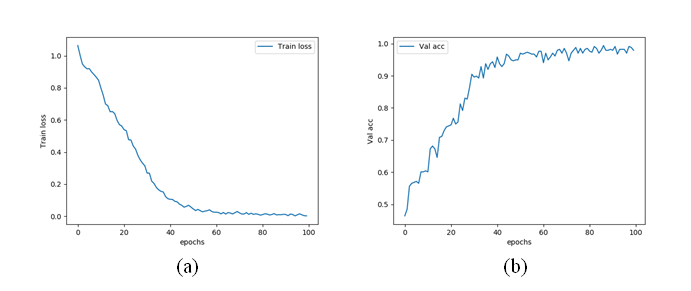
图4:训练集的误差变化曲线和验证集的准确率变化曲线
如图4所示,随着训练次数的增加,训练集上的误差下降,在训练四十次后趋于稳定。与此同时,验证集的准确率也在逐步上升,同样在训练四十次后趋于稳定。
5.表1为Vision Transformer与卷积神经网络的性能对比

从表1中可以看出,在CNN图像分类模型中,VGG16的识别准确率最高,为98.51%,但仍低于Vision Transformer的识别准确率。而剪枝后的Vision Transformer在识别准确率不变的情况下,识别单张图像的所需的时间仅为0.010秒。
通讯作者简介

戴翠霞,上海应用技术大学理学院教授,硕士生导师。长期从事研究方向主要有光学相干层析成像、光声成像、荧光成像等生物医学光学成像技术及应用研究。现任中国生物医学工程学会生物医学光子分会委员,SPIE、OSA会员。担任 Optics letters、Optics express、Biomedical Optics Express、Journal of biomedical optics、Journal of Innovative Optical Health Sciences等光学期刊杂志审稿人。近年来作为项目负责人主持了国家自然科学基金项目3项,上海市科委科技创新行动计划项目2项、上海市自然科学基金1项、上海市教委科研创新项目1项,并作为主要成员参加了国家重大仪器项目,科技部重点基金、武装部重点支持项目、上海市科委科技攻关项目等多项项目研究。在国际重要学术期刊上发表了50多篇论文。