数据量的爆炸增长对现有存储系统带来新的挑战,消除冗余信息优化存储空间效率成为缓解存储容量瓶颈的重要手段,数据去重是消除信息冗余的主要技术之一。
为了实现高性能的在线数据去重,在内存中采用快速索引以判别是否存在重复数据。采用布隆过滤器等固定容量的索引方法描述可扩展数据集合有两个明显缺点。首先,若集合元素的实际数量超过索引的设计容量,则需要较大的时间和空间开销重建整个索引;其次,若集合基数需要很长的时间才能增长到索引的设计容量,则索引需要长期占据不必要的内存资源,降低了内存空间利用率。
武汉光电国家实验室信息存储与光显示功能实验室周可教授研究组提出动态布隆过滤器阵列(Dynamic Bloom filter Array, DBA)用于索引存储系统中的可扩展数据集并快速判断其中的重复元素。DBA由可动态创建的布隆过滤器组构成,以按需调整索引容量和提高内存空间效率。同组的布隆过滤器具有同构的数据结构和优化的内存数据布局,从而可提高元素查询效率。DBA通过局部调整布隆过滤器成员的设计容量或误判率阈值,可在扩容过程中有效控制整体查询准确度。通过将布隆过滤器成员关联到不相交的数据子集,DBA可根据查询结果快速定位疑似重复数据元素。基于备份数据指纹序列的实验结果表明,误判率上限阈值为1/214的DBA在扩展到初始设计容量的160倍时,能够保持4.5105指纹/秒的查询性能,3倍于现有动态布隆过滤器(DBF)方法在同等条件下的查询性能。此外,DBA在可扩展性、误判率控制和内存空间效率等方面均优于现有的DBF方法。
研究工作全文发表在IEEE Transactions on Parallel and Distributed Systems VOL. 25, NO. 4, APRIL 2014。
该研究工作得到国家自然科学基金重点项目(No. 61232004)、国家重点基础研究计划项目课题(No. 2011CB302305)的资助。
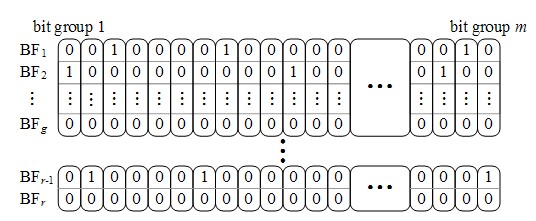
DBA在内存中的位布局
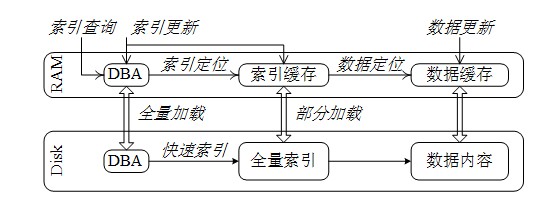
DBA在单存储节点内的部署方式
(责任编辑:陈智敏)