近日,华中科技大学武汉光电国家研究中心张新亮、董建绩教授团队提出了一种用于多模态深度学习的可训练衍射光学神经网络。利用光的相干性和叠加性,大量片上衍射单元可以通过光的衍射在不同模态配置下模拟神经元互联。在光学神经网络训练完成后,只需要一次光的前向传播即可得到推理结果。该工作有望为低功耗人工智能大模型提供潜在的解决方案。相关成果以 Multimodal deep learning using on-chip diffractive optics with in situ training capability 为题,发表在《Nature Communications》期刊上。
多模态深度学习在支持生成式人工智能(AIGC)领域内不同数据类型的处理和学习方面发挥着关键作用。以ChatGPT为代表的人工智能大模型已经突破了单一模态的限制。然而,这类大模型需要大量计算资源来进行参数优化和推理。在后摩尔时代,微电子处理器面临尺寸微缩和功耗剧增的困境,难以满足人工智能应用不断增长的计算开销。但光学神经网络可以在光的多个维度编码信息,并通过光信号在光子器件中的传播来实现计算。“传播即计算”的特质使其天然地兼具高并行性和高能效,有望成为低功耗人工智能的潜在解决方案。
近年来,大量光计算架构已经被提出并在人工智能任务中得到验证,例如Mach-Zehnder干涉仪网络、用于波分复用处理的微环调制器阵列、以及基于相变材料的Crossbar等光子计算核架构。然而,由于光子计算核的计算规模通常较小,因此单个推理任务需要多次调用光子计算核,这导致频繁的光电转换和额外的能量消耗。此外,大多数用于深度学习的光子处理器由于缺乏足够的光域训练参数和在线训练能力,只能处理单一的数据模态。因此,可用于多模态深度学习的光学神经网络是一个非常有价值的研究课题。
针对多模态人工智能的需求,研究人员提出了训算一体的光计算新架构和“黑盒式” 光域在线训练思想。基于上述基础,研究人员设计了可训练的衍射光学神经网络(TDONN)芯片,成功实现了三种不同模态(视觉、听觉和触觉)的四分类任务,突破了光计算的单一模态限制。图1a展示了用于多模态分类任务的光学神经网络模型,它由三部分组成:输入层、隐藏层和输出层。通过特征提取和特征融合,从视觉、听觉和触觉等不同模态的数据集中得到一个特征向量,作为光学神经网络的输入。在隐藏层中,神经元按多层布局排列,并在训练过程中调整各神经元之间的连接权重,以实现目标功能。在输出层中,每个输出端口的输出功率映射到各分类标签的概率。研究人员在硅基光电子平台上制作了相应的TDONN芯片用于概念验证,图1b展示了该芯片的结构。输入层由16个强度调制单元组成,用于加载输入数据,并通过片上调制将特征向量的元素值编码为光信号的强度。隐藏层由排列为五层的可调衍射单元组成,每层有16个可调衍射单元,这些衍射单元用于模拟隐藏层中的神经元。图2展示了“黑盒式”光域在线训练思想,将芯片内部视为黑盒子,根据目标功能定义代价函数,通过反馈算法调参迭代,完成网络的训练。与国际同行对比,该方法具有普适性、抗工艺误差和环境干扰的优势,而且不依赖耗时的数字计算机仿真。
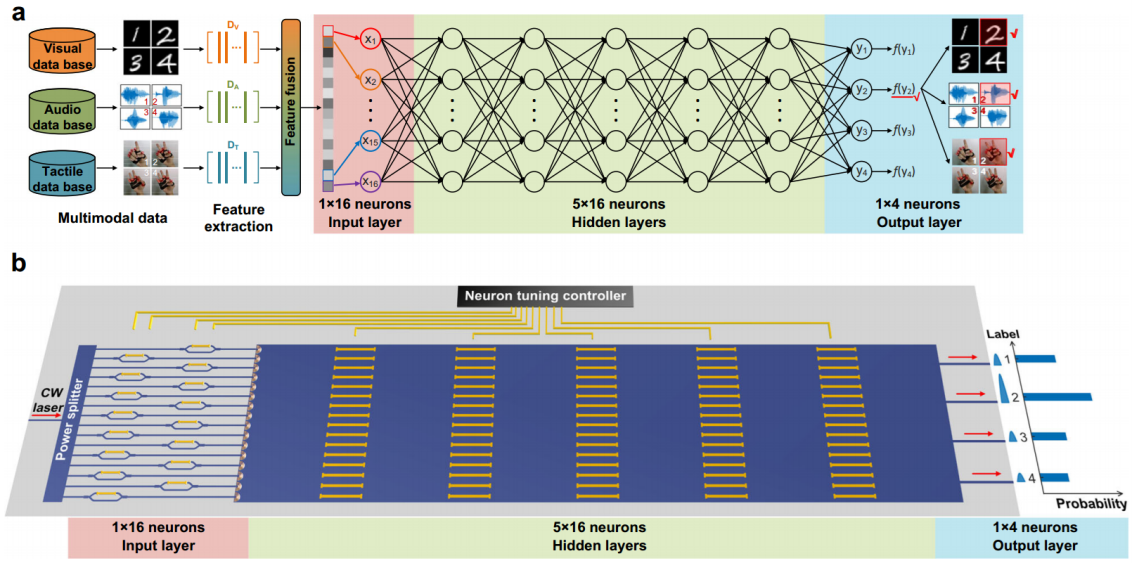
图1. 训练计算一体的光计算新架构。a 多模态分类的光学神经网络模型,b 概念验证芯片的结构
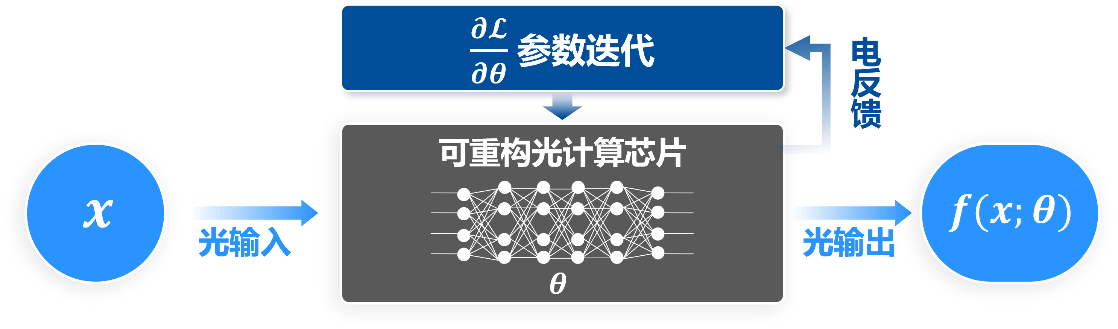
图2. “黑盒式” 光域在线训练示意图
强大的可重构性是计算硬件在多模态深度学习中不可或缺的重要能力。该研究工作提出的TDONN芯片支持光域在线训练,其训练过程可以分为两步:第一步是对不同模态的输入数据进行预处理以提取特征;第二步是对芯片的可调衍射单元参数进行训练和优化以实现目标功能,如图3所示。在第二步中,研究人员还开发了用于光学神经网络的梯度下降算法和dropout机制,用于训练的快速收敛。在完成训练之后,TDONN芯片只需要一次光的前向传播,就可以直接根据输出端口的功率分布得到推理结果。
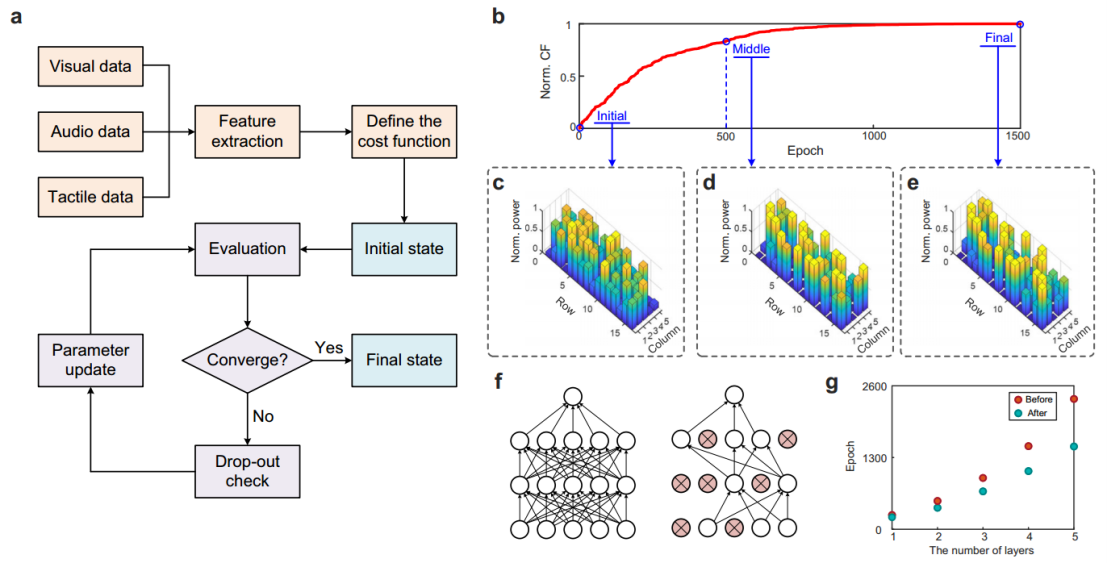
图3. TDONN芯片的训练
研究人员使用了三种不同模态的数据集来验证TDONN芯片的多模态推理能力。图4a-d、e-h、i-l分别显示了视觉、听觉和触觉三种模态的分类概率分布。实验结果表明,通过光域在线训练,TDONN芯片具有实现光域多模态分类任务的能力。为了进一步验证TDONN芯片的推理能力,每种模态分别使用100个测试数据对该芯片进行了测试。图4m-o展示了三种模态的测试数据的混淆矩阵,分类准确率分别可以达到86%、82%和89%,平均准确率为85.7%。
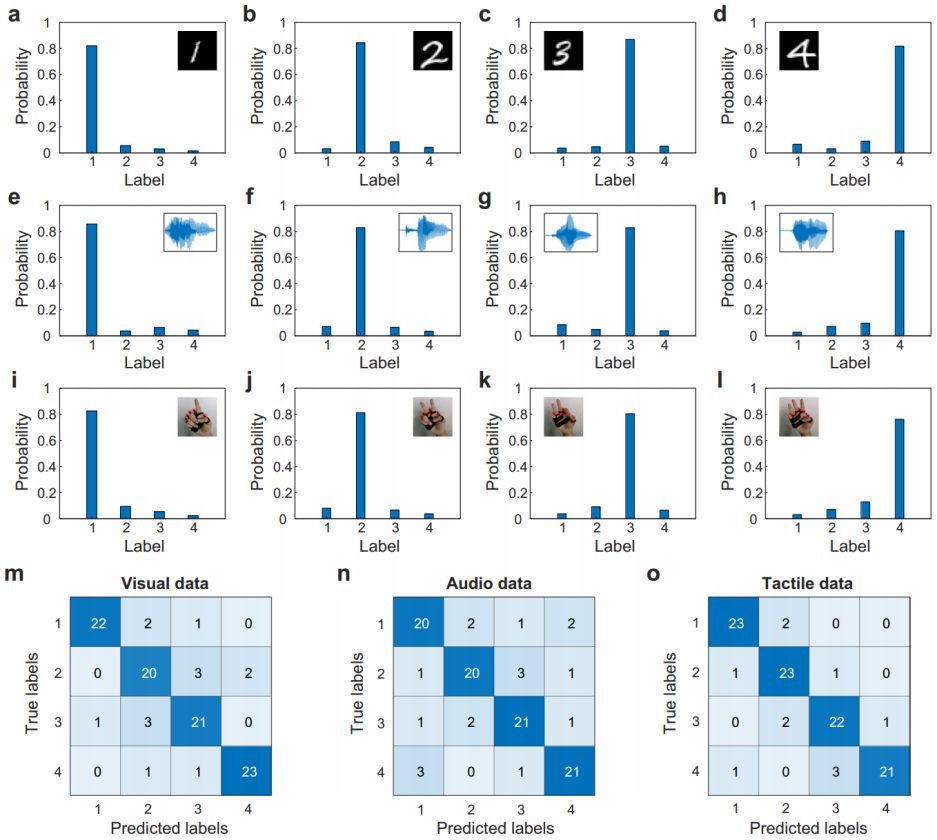
图4. 多模态数据的推理结果
本研究提出了一种训算一体的光计算新架构,并通过一个多层衍射光学神经网络芯片演示了其在多模态推理中的应用。该芯片的训练和推理均在光域进行,具有高算力(217.6 TOPS)、高计算密度(447.7 TOPS/mm2)、高系统级能效(7.28 TOPS/W)、低光学延迟(30.2 ps)、可重构等优点,与单层光学神经网络相比,算力提升了一个数量级。该芯片成功实现了三种不同模态(视觉、听觉和触觉)的四分类任务,准确率与数字计算机相当。训练计算一体架构和“黑盒式”光域在线训练思想为多模态光学神经网络研究开辟了新的可能性,同时也为低功耗通用人工智能铺平了道路。
华中科技大学武汉光电国家研究中心的成骏伟博士为该论文的第一作者,董建绩教授为通讯作者。论文的合作作者还包括上海理工大学顾敏院士和张启明教授,香港中文大学黄超然助理教授,华中科技大学的张新亮教授和周海龙副教授等。该研究得到了国家重点研发计划和国家自然科学基金的支持。
文章链接:https://www.nature.com/articles/s41467-024-50677-3